Use of Windows Exception Handling Metadata
64-bit Windows and the Intel 64 environment have brought a number of changes to the way processes interact with their environment. Among these is the elimination of the base pointer by default, and with it, the ability to unwind the stack based only on the values of the stack and base pointer and the values at these locations on the stack. This frees RBP up for use as a general purpose register in addition to the 8 new ones introduced in the new architecture.
When an exception occurs, one of the first things to do is to unwind the stack looking for a handler; this involves looking through each stack frame starting with the current one, looking for a frame corresponding with a function we know how to handle exceptions in. In order to do this, we need some mechanism of determining the length of stack frames, which is variable; otherwise, we have no way of knowing which address will be returned to and can't determine the identity of the calling function. The traditional method of doing this is to use the base pointer to determine the width of each stack frame, storing the base pointer at a well-known location right next to the return address. However, as the base pointer is gone in 64-bit Windows, a new method of accomplishing this in the event of an exception is required; this method is the stored unwind data. It is computed at compile time, and stored in the .pdata section of the resultant PE; the structures are documented in the MSDN library.
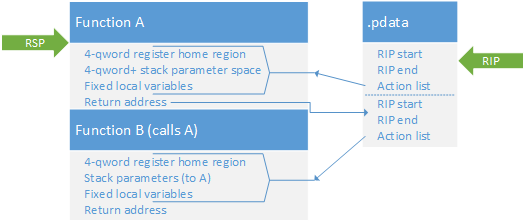
I show the difference between the old and new ways (there are two new ways, depending on whether alloca() is used) in the following diagrams. Note that the arguments passed on the stack, if present, are effectively local temporary variables in the calling function.
The RIP pointer in these diagrams is not pointing to the position of RIP, but rather indicating the range within which RIP lies; the item it points at is the exception handling metadata for the current function.

Simple 32-bit way
64-bit stack frame and lookup, without alloca()
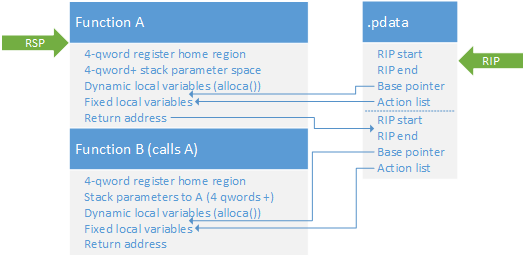
This is a great simplification of the way this actually works. At the time the PE is loaded, the contents of the .pdata section (technically the xdata which are referred to by .pdata) are imported by the runtime and addresses are translated from image-relative to process-relative, which will have consequences to be described later. However, in the vast majority of cases this data does not change and continues to be valid if the addresses in it are translated. This of course has very little impact on static analysis, but it is at least theoretically possible to obfuscate this data in the PE by rewriting it at runtime. Additionally, the base pointer item in .pdata is not itself a frame pointer; it identifies the register which will act as a frame pointer. The structure of the unwind data is also somewhat more complex, but it is logically reducible to what is shown. I have also elided the semantics of the "action list", which is really a derivation of the unwind operations structures. I've also left out the concept of leaf functions (the functions in the diagrams are termed "frame functions"); I will describe leaf functions below.
There are other variants of these structures too. For instance, according to the MSDN, a function could establish a frame pointer in order to make the parameter-passing and register home regions dynamic; this would really only be advantageous where the function sometimes calls a function with very large stack parameters and sometimes does not, and as also stated in the MSDN, the current VS2012 compiler does not do this thing. However, it is important to note the difference between the dynamic and static (eg. with and without frame pointer) which makes this possible.
In 64-bit Windows, the function prologue and epilogue are standardized. They perform a certain set of defined operations, which can be enumerated; these are what the unwind operation codes describe in the unwind data. Once the stack has been set up, it remains constant for the body of the function (those parts other than the prologue and epilogue) for functions without a frame pointer, and the representation of this data is correspondingly uncomplicated. For those functions which establish a frame pointer, only the portion of the stack prior to the frame pointer remains static throughout the body, and only that portion needs to in order to correctly establish the size of the stack frame during unwinding.
The presence of this data, necessarily in an exhaustive form, presents interesting possibilities for reverse-engineering and analysis. Particularly, the data records the action of function prologues with reference to the range of instructions to which they apply. From this and the definition of a function prologue, it follows that each range of addresses will directly correspond to a function, and so even without complete debugging information it is possible both to unwind the stack without the frame pointer, and create a list of function entry points for disassembly. This provides a useful starting point for recovering unpublished symbols, and can be used to significantly increase the reliability and completeness of disassembly.
To briefly define how this data is stored, three structures exist: runtime function entries, listing the start and end address of a function; unwind info entries, describing the character of the function's exception handling (with a 1:1 relationship to runtime function entries, though a 1:n relationship would be compatible); and unwind code entries, with an n:1 relationship to unwind info, enumerating the action of the runtime function's prologue on the stack.

UnwindInfo
Full documentation of these structures is provided in the MSDN.
Unfortunately, with this data come a number of caveats which are slightly more obscure.
Firstly, not all functions are required to have exception handling information. If the information does not exist for some value of the instruction pointer, it is assumed that the function is a leaf function with no exception handling: that is, in C++ terms, it contains no try-catch or try-catch-finally blocks, allocates no stack and saves no registers, and calls no functions (though the method for handling these would accommodate a series of "leaf" functions which pass parameters by volatile registers only and use no stack except that used by the CALL instruction). While this is fine for exception handling (just pop the instruction pointer and recurse), it will obscure the entry point of any leaf function which immediately follows another leaf function.
Secondly, if the target operation is stack unwinding, it is important to realize that stack unwind info can be chained. In this case, the unwind info entry may have its own stack operations, but they must be taken in union with another set. The other set is pointed to indirectly; a runtime function entry is placed after the unwind info entry, and the unwind info associated to it applies additively to the original function. These chains can be arbitrarily long, and may semantically contain cycles. Allegedly, this chaining reduces the size of .pdata in the image.
Third, an undocumented case exists (apparently used exclusively within Windows and Office) whereby rather than pointing to an unwind info structure, a runtime function entry may point instead to another runtime function entry. The same offset is used for both pointers; as the starting addresses of unwind info and runtime function entries are guaranteed to be aligned, the least significant bit of the unwind info pointer is used as a flag. If it is set, it should be masked out, and indicates that the pointer is actually to another runtime function entry which contains the unwind info for the function.
Fourth, while it is not clear in the documentation, the ending address of a runtime function entry does not indicate the last address of a function, but rather the first address after the function epilogue (eg. the first address not in the function).
Lastly, while in the vast majority of cases the entirety of the exception handling information is computed at compile time and is static, an API is provided by which dynamic code can add exception handling entries at runtime. While static analysis of dynamic code is obviously suboptimal and not aided by the use of compile-time exception handling data, it is also possible to generate a compiled application which places "private" (but not runtime-generated) functions adjacent to each other and dynamically creates exception handling information for them at some point during runtime. This will effectively obscure them from a .pdata-based analysis.